Transformer基本结构
毕设背景调研之transformer基本结构
Transformer
pytorch代码实现:
Transformer的PyTorch实现 - mathor (wmathor.com)
The Annotated Transformer (harvard.edu)
原理+结构+基本运作流程:
Transformer详解 - mathor (wmathor.com)
Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)
以下图片大部分来自于知乎
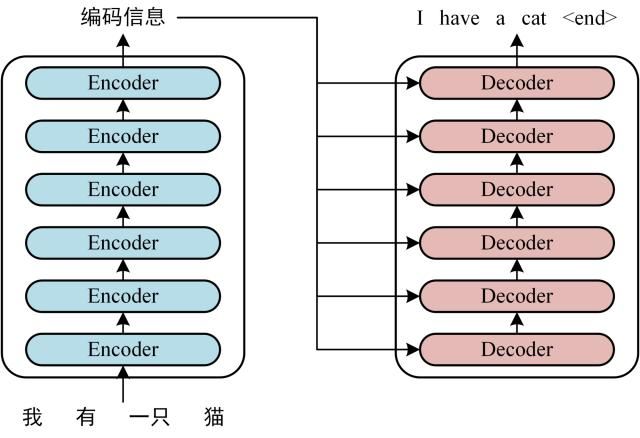
整体结构
预处理 Embedding
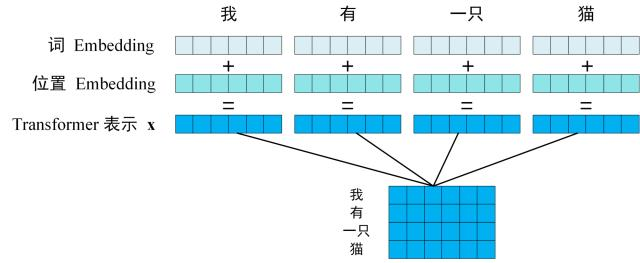
一个长度为$n$的序列会被编码为一个$n\times d$的矩阵
- 其中$d$表示每个序列元素编码后的长度
- 该编码包括了该元素本身值的信息和其所处的位置信息
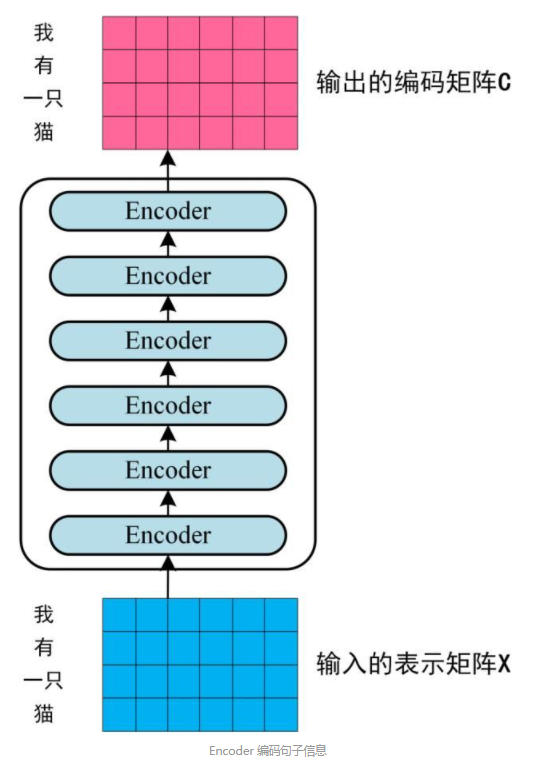
Encoder
每个Encoder的输入和输出的维度均相同,且于Embedding后的输入序列长度相同
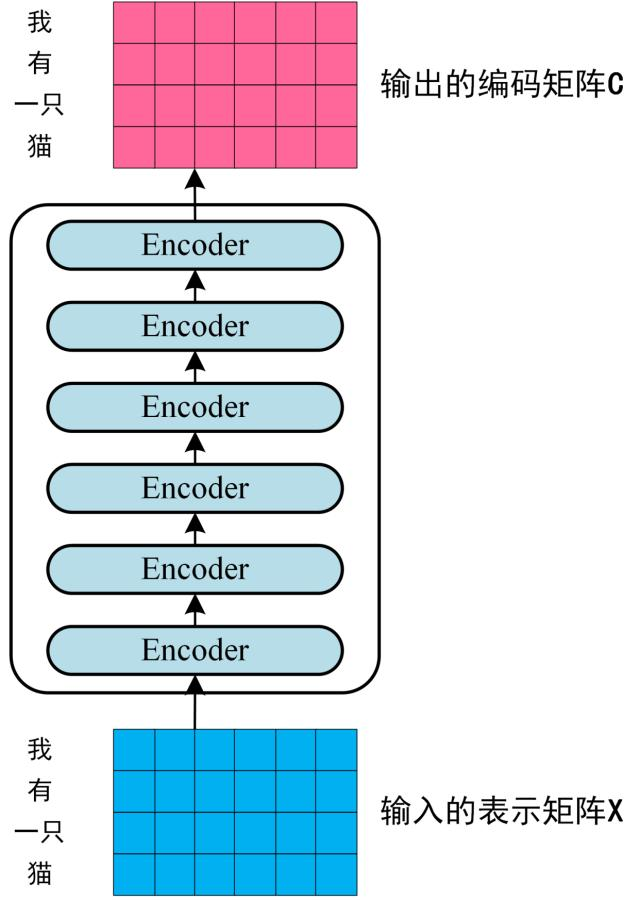
- $X$和$G$的维度相同
Decoder
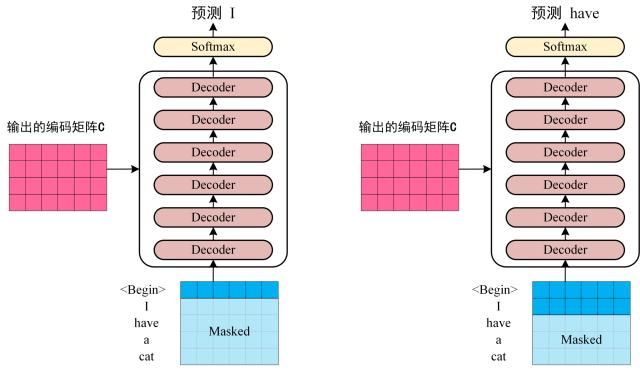
-
Decoder接收编码矩阵$C$
- 向Decoder输入一个开始符
,其输入一个单词"I" - 将二者都输入Decoder得到下一个单词”have”
- 依次类推
问题:
- Mask意义是什么?
- Decoder输出的序列的长度是确定的?
Self-attention
QKV计算
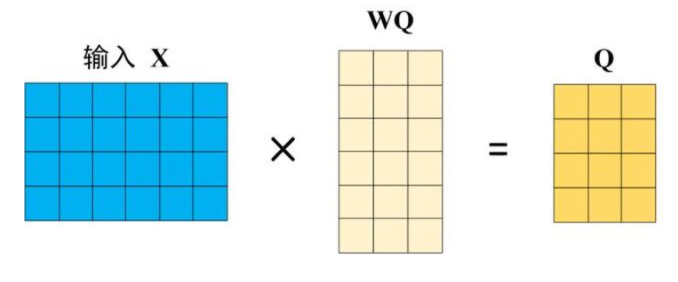
self-attention
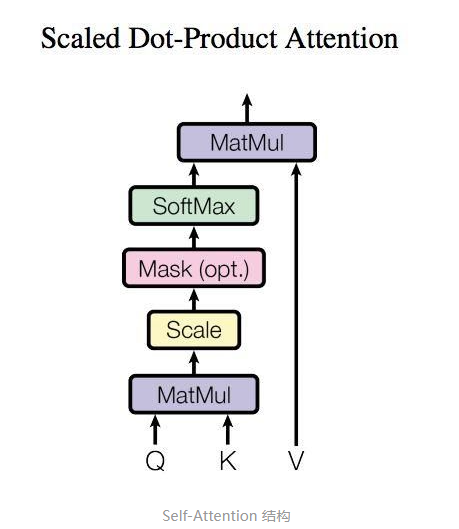 \(Attention(Q,K,V) = \text {softmax} (\frac {QK^T} {\sqrt d_k})V\)
\(Attention(Q,K,V) = \text {softmax} (\frac {QK^T} {\sqrt d_k})V\)
- X, Q, K, V中每一行都代表一个词
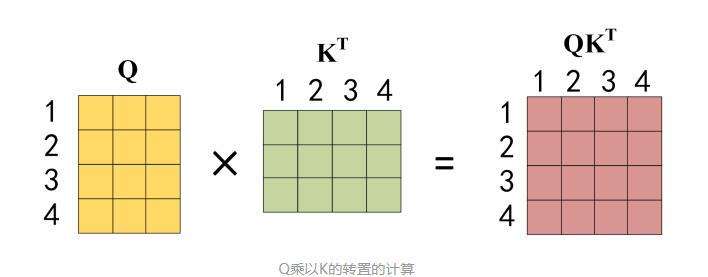
-
$QK^T$中每个元素都代表句子中单词
-
使用softmax计算每一个单词对其他单词的attention系数
- 对矩阵中每一行进行softmax
- 比如第一行表示1 对 1 2 3 4的attention
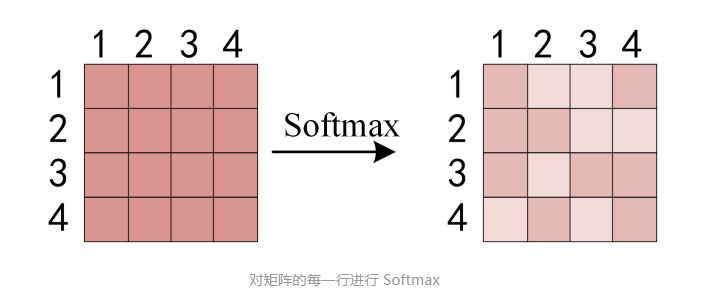
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z
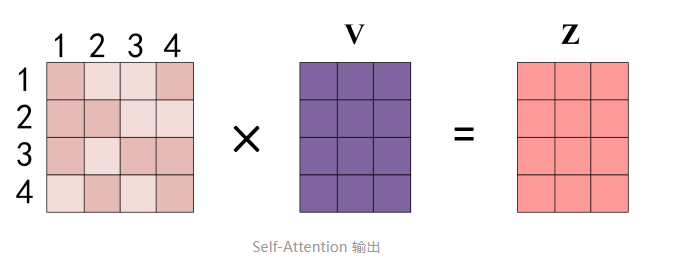
看下来一个self-attention中需要学习的参数也就只有QK,QW,QV三个线性变换矩阵
self-attention中的输入和输出的维度是不同的
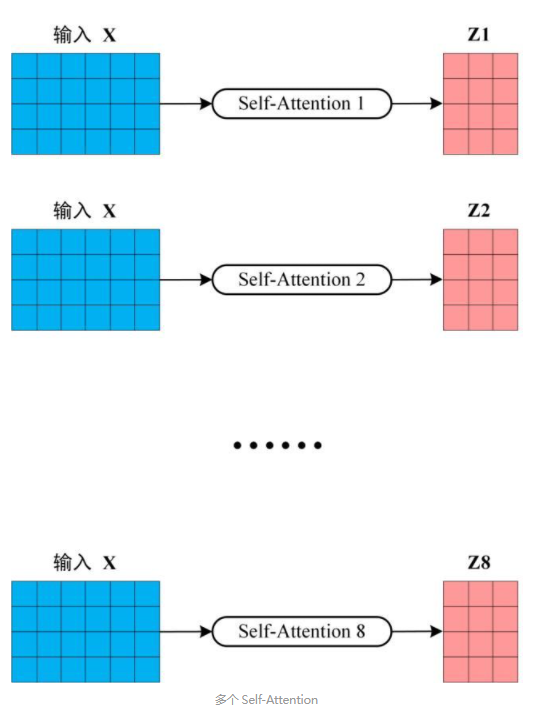
Multi-Head Attention
多个attention+concat+linear
拼接+linear层最终输出和$X$相同维度的输出
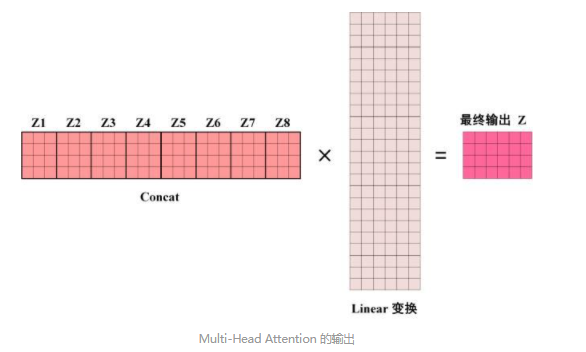
一个有N个头的attention中需要学习的参数有:
- N X 3(QKV)个线性变换矩阵
- 最后的Linear变换矩阵
多头attention中输入和输出的维度是相同的
Encoder
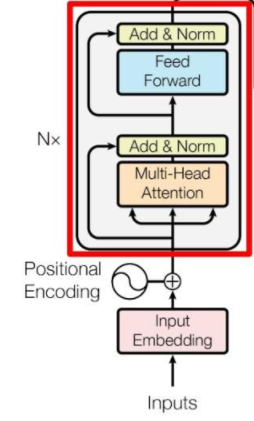
Add & Norm
\[\text{LayerNorm} (X+\text{MultiHeadAttention}(X)) \\ \text{LayerNorm} (X+\text{FeedForward}(X))\]和ResNet中的一样
Feed Forward
两层全连接,第一层激活函数为Relu,第二层无激活函数 \(\max(0, XW_1 +b_1)W_2 +b_2\) 其输出维度和输入$X$一样
假设$X$维度为$n\times d$
可知$W_1/W_2$ 维度分别为$d\times k$和$k \times d$
在原结构中$k$会比$d$大,于是形成一个类似瓶颈的结构,这也是诸多轻量transformer对原模型改进的重点
整体Encoder输出
由于多头attention,add&norm,feed forward的输入和输出维度均相同,故encoder的输入和输出的维度也相同
Decoder
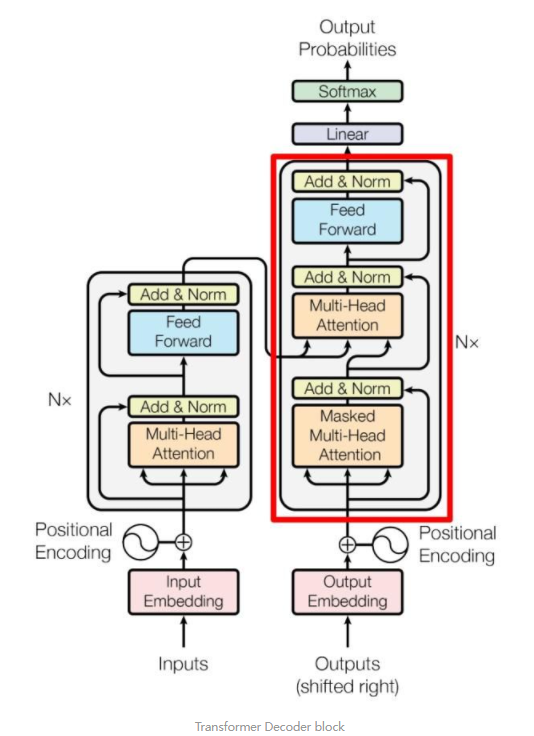
Decoder block结构中包括两个多头attention和一个feed forward
- 其中第二的多头attention中的K/V来自encoder输出的编码矩阵,Q来自上一层的输出
- 第一个多头attention的采取mask操作(训练过程中)
预测
不断输入,直到输出
?
训练时预测
使用mask
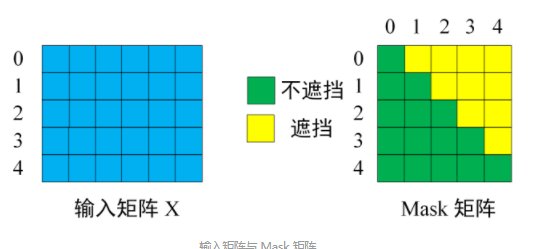
mask操作在$QK^T$之后,softmax前
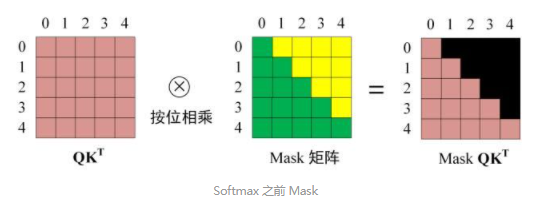
- 绿色:1
- 黄色:0