Bigdata Opensource Eco
大数据生态
开源
Hadoop
Hadoop = HDFS(存储) + MapReduce(计算) + YARN(资源调度)
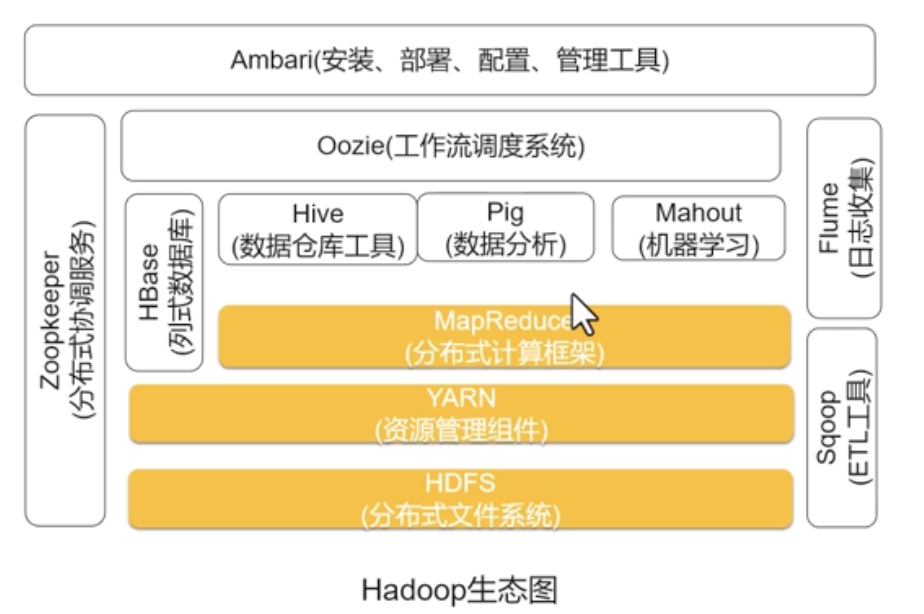
HDFS
-
主从结构
- NameNode x 1
- 元数据
- DataNode x N
- NameNode x 1
-
适合一写多读场景
MapReduce
-
一种编程模型,用于大数据集并行运算,用于离线数据处理
- 执行过程
- 输入文件分片
- 空闲节点分配map或reduce任务
- map: 读数据转为kv形式,落盘并发送给reducer
- Reduce: 将同一个k对应的v合并,形成<k, list
>,reducer对list 中数据计算得到结果输出到HDFS中。
- 不能实时计算,不适合流计算,不适合dag
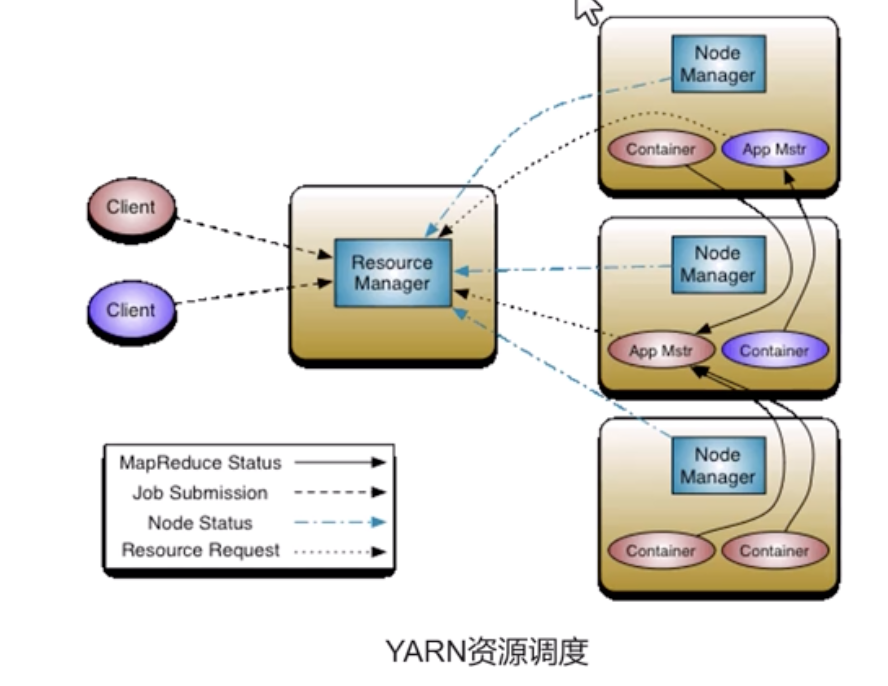
YARN
- 资源管理器和调度平台
- 对mapreduce任务的资源进行调度
- 架构
- ResourceManager
- 整个集群分配与管理
- yarn中主节点
- NodeManager
- RM的从节点
- AppMaster
- 应用程序资源分配
- 每个mapreduce是一个应用程序
- Container
- 每个AM有多个map和reduce任务
- 每个任务对应一个container
- ResourceManager
理解:
- RM和NM表示物理上的主从结构
- AM和container对应执行任务时逻辑上的主从
- 调度流程
- client向yarn提交应用程序
- rm和nm通信并启动一个am
- nm上的am启动完成后向rm注册并申请资源
- am向rm轮询申请资源
- am申请到资源后向对应nm提出启动container的申请
- am运行完成后向rm报告并释放资源
Hive
- 基于hadoop的数据仓库的etl工具
- 不存储数据,存储依赖hadoop的hdfs
- 提供映射将hdfs的数据文件映射为表并支持sql
- sql查询基于mapreduce,查询非实时
HBase
-
准实时查询
- 分布式,面向列的开源数据库
- 一般rdb是行存
-
底层文件存储依赖HDFS
- kv型数据库
- key = row_key+column_family+column_qualifier+time_stamp
Mahout
- 机器学习库
Pig
- 基于hadoop的数据分析平台
- Pig latin语言实现mapreduce
- 存储基于hdfs
zookeeper
- 分布式协调服务
- 解决分布式集群中系统一致性问题
功能
- 配置管理
- 名字服务
- 分布式锁
- 选举机制
注册中心
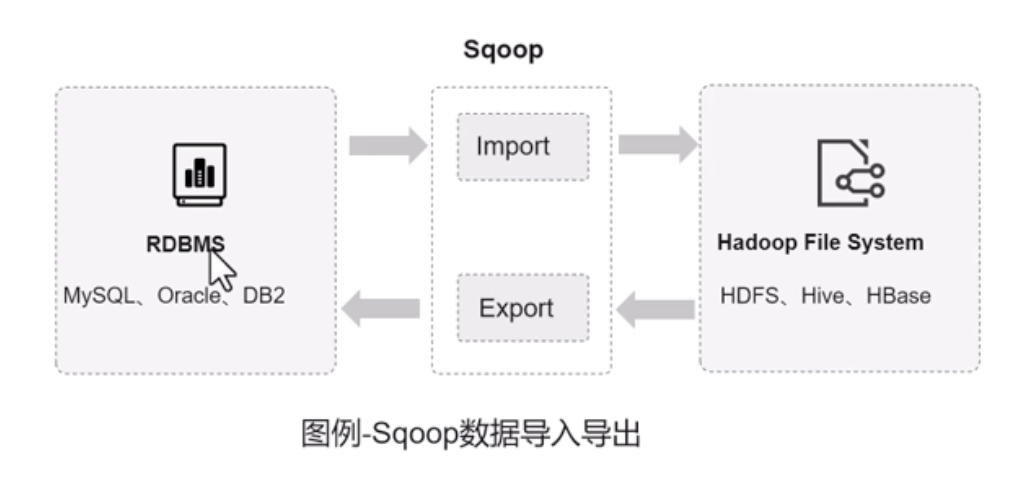
Sqoop
- 数据采集工具,负责业务系统关系型数据库和hadoop之间数据传递
- 业务数据
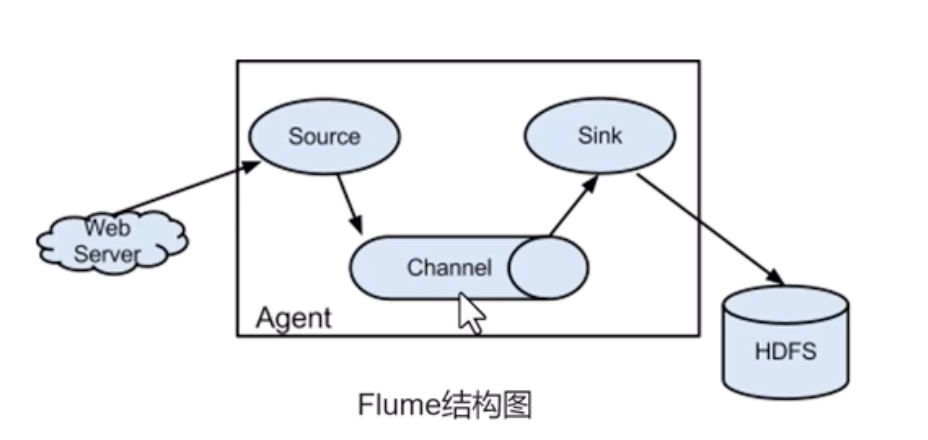
Flume
- 日志聚合系统
- 可用于离线或实时数据
Ambari
- 基于web的hadoop集群配置、管理和监控

定位类似data works?
oozie
基于工作流引擎的框架,用于管理hadoop的mr工作流程调度系统
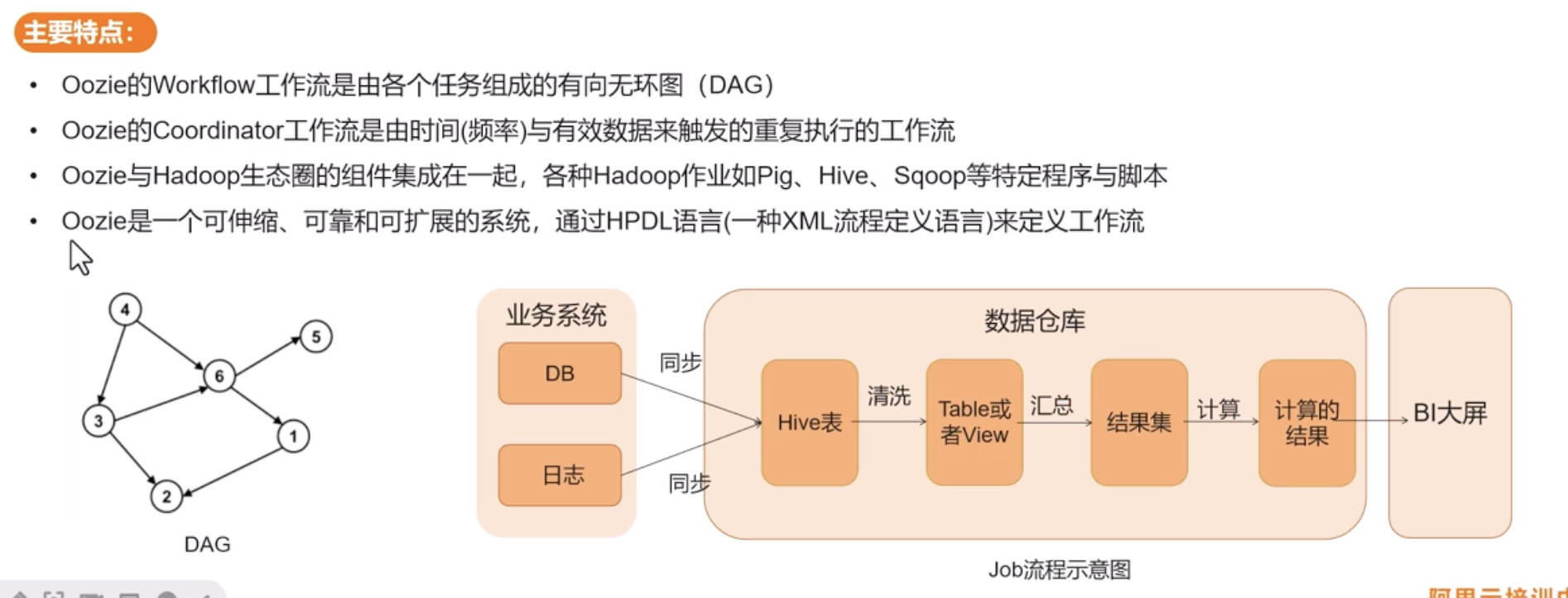
定时调度+节点依赖
Spark
- 分析引擎,支持实时和离线
- 基于内存计算,保证实时
Why spark?
- Mapreduce不支持实时
- 只有map和reduce不够灵活
Spark生态
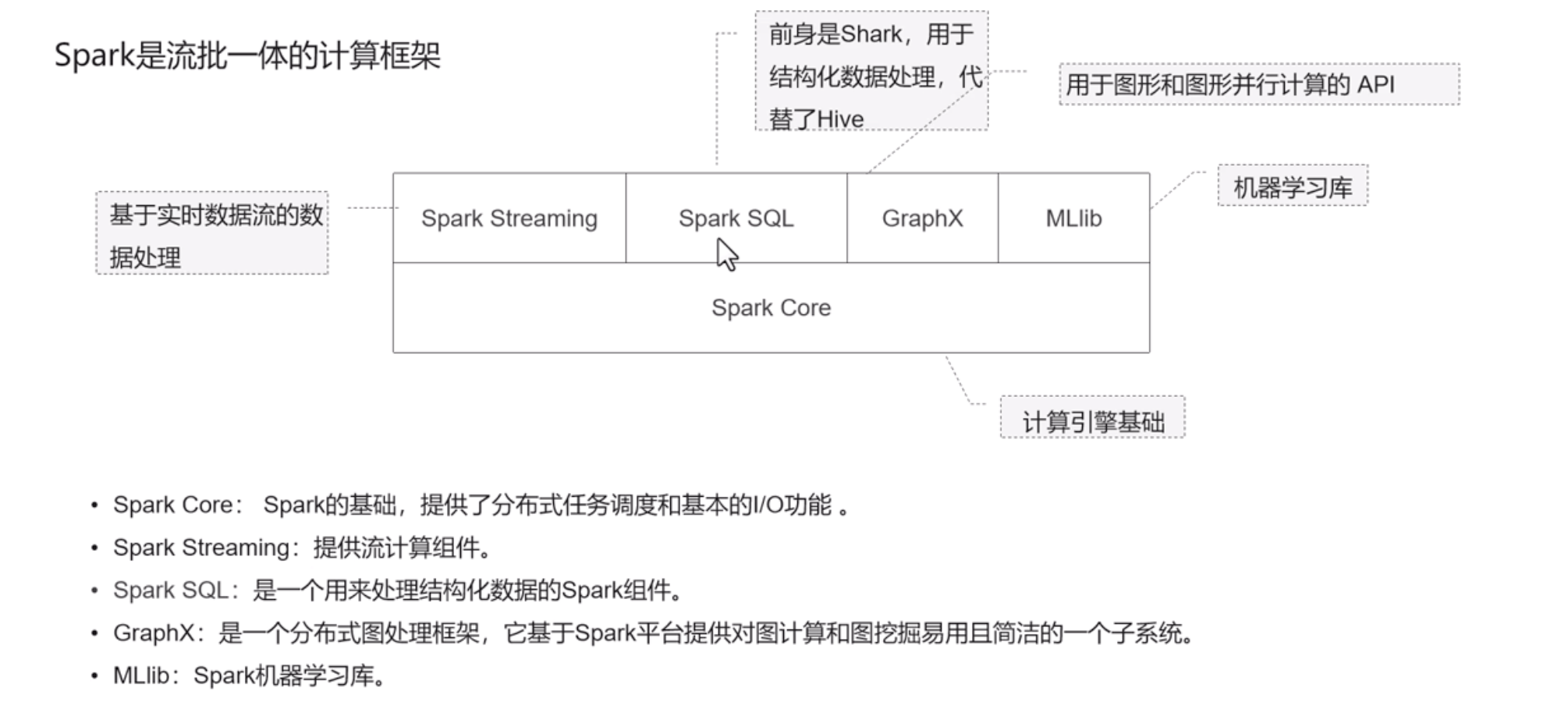
Spark vs Hadoop
hadoop和spark不互斥
- spark的数据存储基于hdfs
- spark的资源调度可以使用yarn
- hadoop是分布式系统基础框架,spark是统一计算引擎
- spark基于内存和迭代运算简化的mapreduce计算过程
- spark可以用于实时数据
其他
- DataX:异构数据源离线同步工具
- 定位如sqoop,但支持的数据源更多
- azkaban:任务调度系统,解决任务之间的依赖关系
- 保证任务按dag依赖关系执行
- 类似oozie?
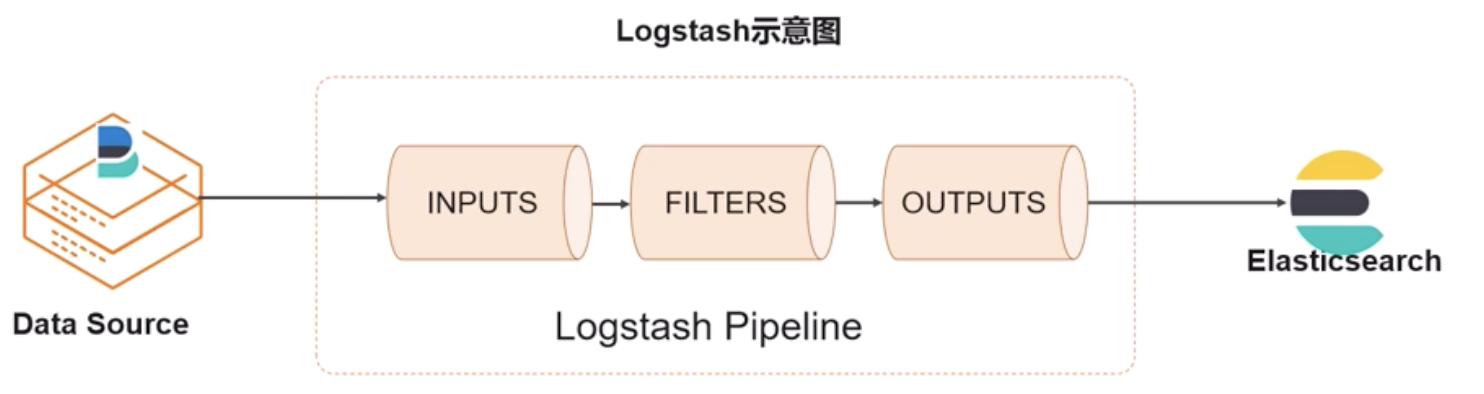
- logstash:服务端数据处理管道
- 实时数据,定位类似flume?
- kafka:mq
- 在线和离线都支持
- 支持和flume、spark、flink、storm集成
- flink:流数据
- spark是微批处理
- 用于日志分析系统、监控预警、实时推荐