llama2 paper
LLAMA-2论文
2023-7
Helpfulness and safety
llama2是一系列经过预训练以及调优后的LLM模型,参数大小从70亿(7b)到700亿(70b)。
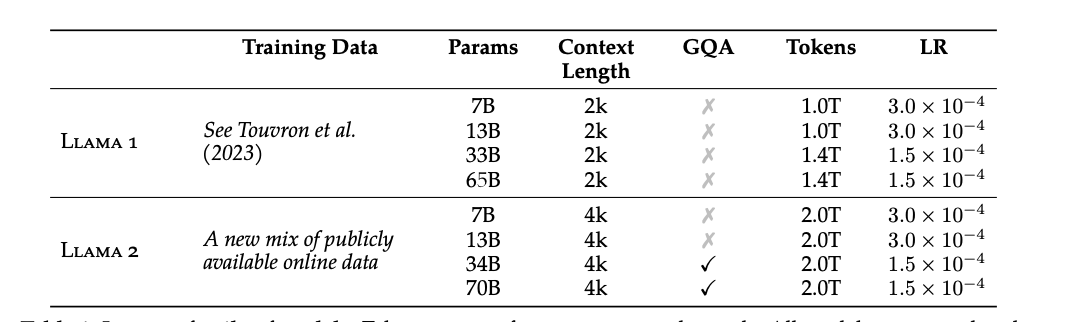
Llama2是llama1的升级版,在一个新的混合公开数据集上训练。预训练语料增加了40%,模型上下文长度为原来两倍同时使用了Grouped-Query Attention。模型有7B,13B和70B参数的变体。论文中使用的为34B版本,由于缺少验证,其暂时未发布。
Llama2-chat是专为对话优化的llama2调优版本,其也有7B,13B和70B版本。
组织结构:
- Section2:预训练方法
- Section3:微调方式
- Section4:模型安全
- Section5:关键发现和启示
整体训练过程概述
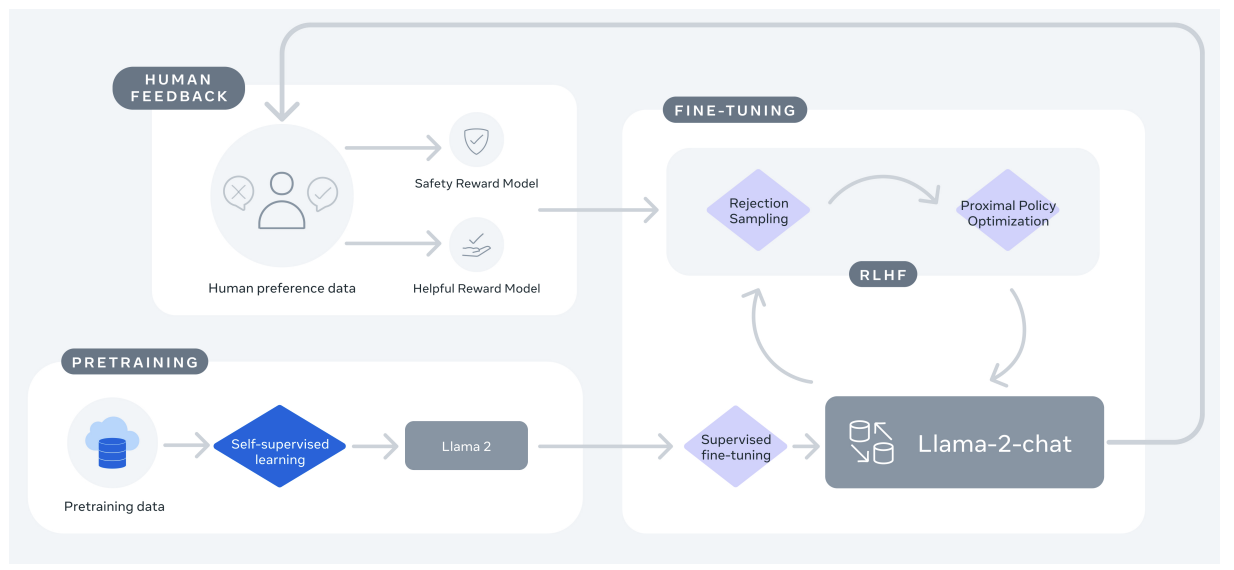
- 使用公开的、可用的在线资源对LLAMA2进行预训练
- 对LLAMA2进行有监督训练调优
- 使用RLHF进行迭代式调优,尤其是拒绝采样(Rejection Sampling)和PPO
Pretraining
沿用了llama的模型结构和预训练方式,相比于Llama1其使用了
- 新的数据集
- 更强的数据清洗
- 更多的token(40%)
- Grouped Query Attention - GQA
预训练数据
- 模型预训练共2w亿token
- 性能和训练消耗的trade-off
- 对最可靠的数据源上采样以增加可行度并降低幻觉
后文有对预训练数据的分析
训练细节
训练设置和模型结构基本和llama1相同
模型结构
- 标准transformer结构
- Pre-norm以及RMSNorm
- SwiGLU为激活函数
- Rotary positional embedding (RoPE)
和LLama1区别
- 两倍的context length
- 使用GQA
训练设置
-
AdamW \(\beta_1= 0.9 \\ \beta_2 = 0.95 \\ \text{eps}=10^{-5}\)
- Cosine学习率
- 2000步warmup
- 最终学习率衰减为最高学习率的10%
- Weight decay = 0.1
- Gradient clip = 1.0
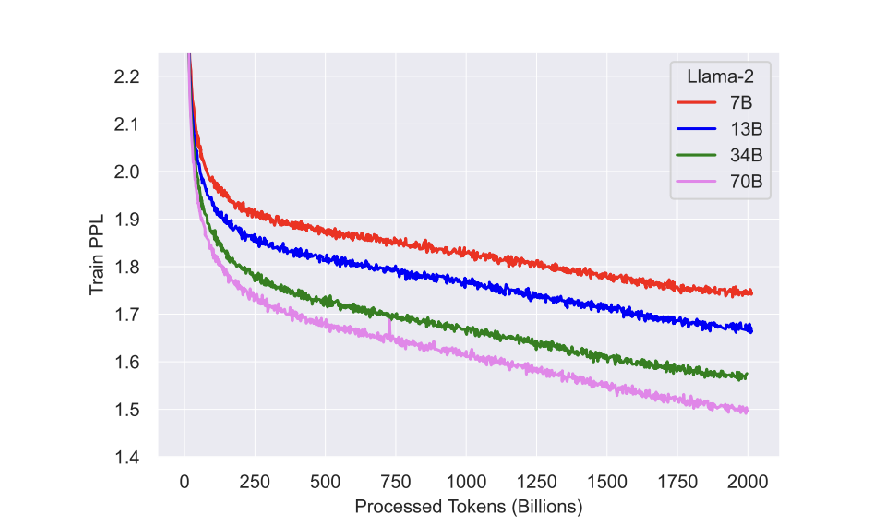
训练过程
经过2w亿个token训练后模型仍未表现出饱和
tokenizer
- bytepair encoding算法的实现
- 所有数字都拆解成单个数字字符
- 使用字节分解所有UTF-8字符
- 所有的训练集共32k tokens
训练消耗
硬件:A100s
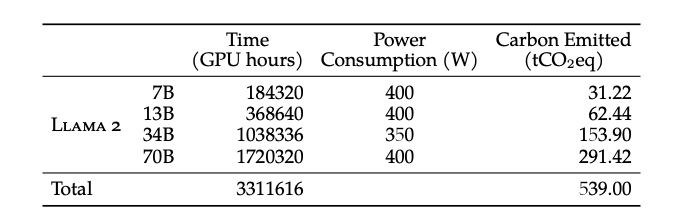
| 大小 | 耗时(GPU) | 温室气体排放(tCO2eq) |
|---|---|---|
| 7B | 18.4wh=21y | 31.2 |
| 13B | 36.8wh=42y | 62.4 |
| 34B | 103.8wh=118y | 153.9 |
| 70B | 172wh = 196y | 291.42 |
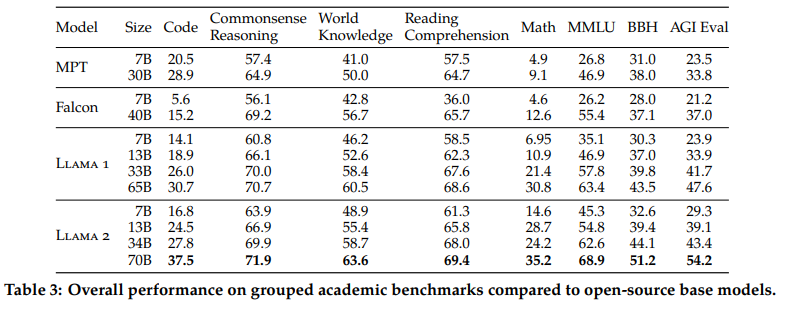
预训练模型性能评估
使用内部的评估库,评估性能取原文和reproduce间的最高值
评估内容包括4个方面:
- code
- Commonsense Reasoning 常识推理
-
World Knowledge 关于世界的知识
- Reading Comprehension 阅读理解
- math
- Popular Aggregated Benchmarks 主流的聚合指标
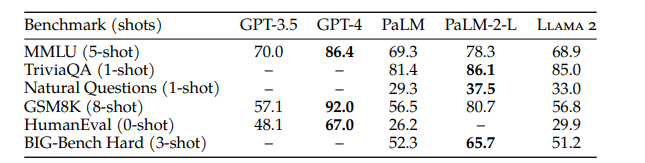
开源模型对比
闭源模型对比
结论: llama2 70B的结果在部分任务上和gpt-3.5的性能相近,但在code方面还有显著差异。总而言之,llama2 70b与gpt-4、Palm-2-l还有巨大性能差距。